起因
自从3月25日起频繁收到线上告警短信,内容为线上某应用的两台实例频繁进行FullGC。
贴其中一种GC监控图
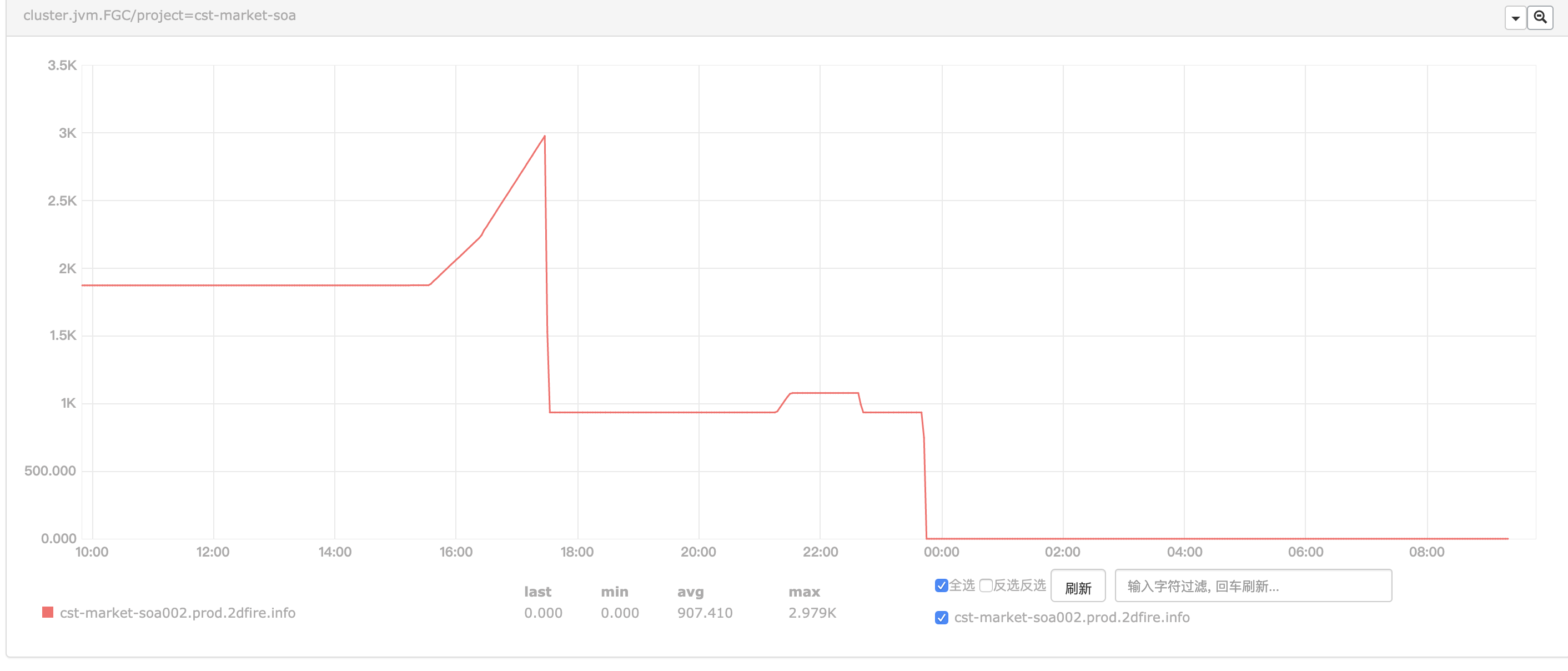
于是上到生产环境
1 | ps -ef |grep java |
1 | sudo jstat -gcutil ${pid} 1000 |
两条命令下去,随机发现实例Old区占用率已然100%,并且从应用重启至今已经发生了3000+次full gc。并且平均3秒会进行一次full gc。
很明显是发生了死循环创建对象之类的问题。
查找问题
首先重启了一下线上的两台实例(一台一台来,总共就两台),发现没过多久GC又上来了,看来是必现问题。既然如此只好dump了,于是使用
1 | sudo jmap -dump:format=b,file=文件名 ${pid} |
这里有一个问题,因为我是跳板机进入的生产环境服务器,然而项目是运行在jetty用户下的,因此这里需要将命令更换一下1
sudo -u jetty jmap -dump:format=b,file=文件名 ${pid}
dump出文件大概4.3个G,下到本地,然后使用 visualVM打开,豁然开朗
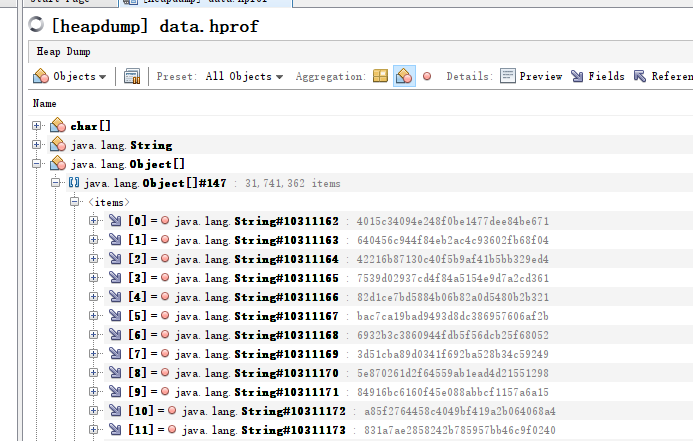

可以看到明显是有一个对象数组引用了3174W+的字符串,导致堆内存被塞满,原因很顺利的找到了。
解决
于是首先想到的是查看这个应用的发布记录,于是可以查到这两天这个应用有过两次发布,将两次发布合并与之前版本比较发现确实是修改了部分代码。
代码与某一个营销活动相关。于是将GC突然增长的点与该活动发布记录相对比,时间完全吻合。
叫上小伙伴一起review代码,发现代码中有显示的while(true)循环,break条件是分页查询数据库直到数据库查询没有数据。看来肯定是这个条件的问题
于是切换到底层SOA,发现查询数据库的分页代码存在严重的逻辑漏洞(还是比较明显的,看来团队测试质量还是需要提高一下)。
因为分页查询的漏洞,导致了数据库查询永远都只查第一页的数据,如果一次查询10K条,那么2次20K,30次30K,无限循环下去。
于是注释代码(保留现场,毕竟不是自己的bug),发布底层SOA应用,然后重启出问题的应用实例。完美解决